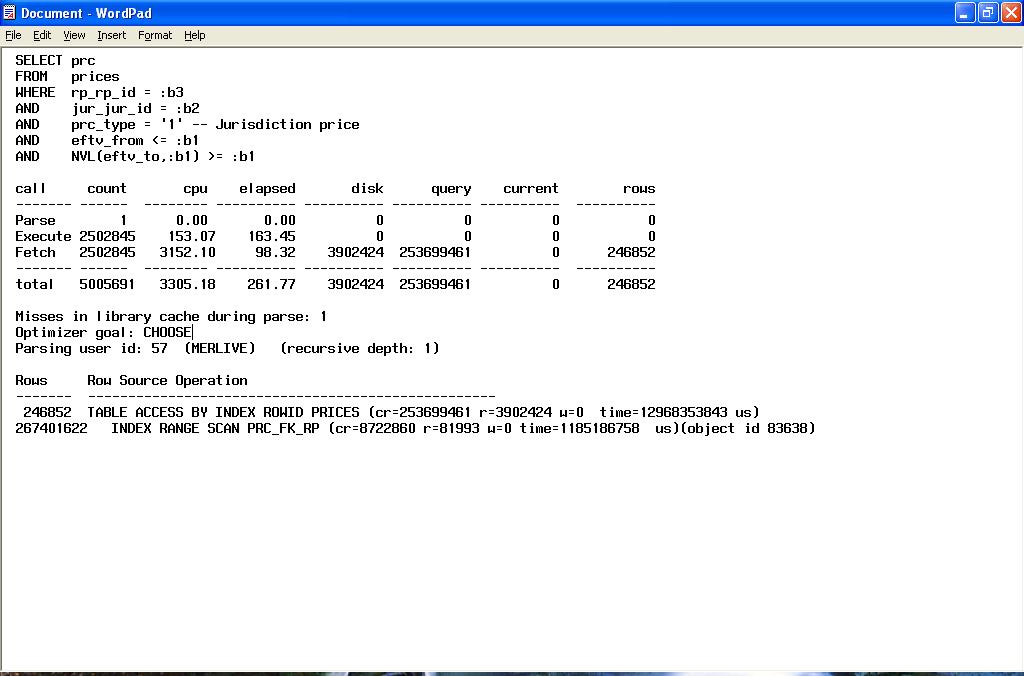
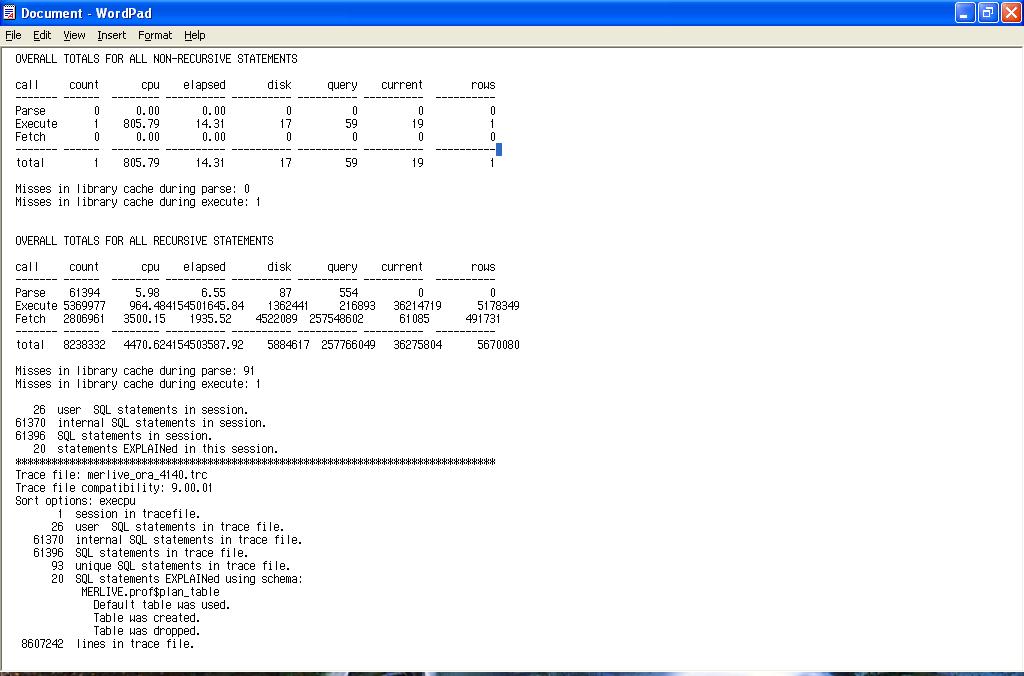
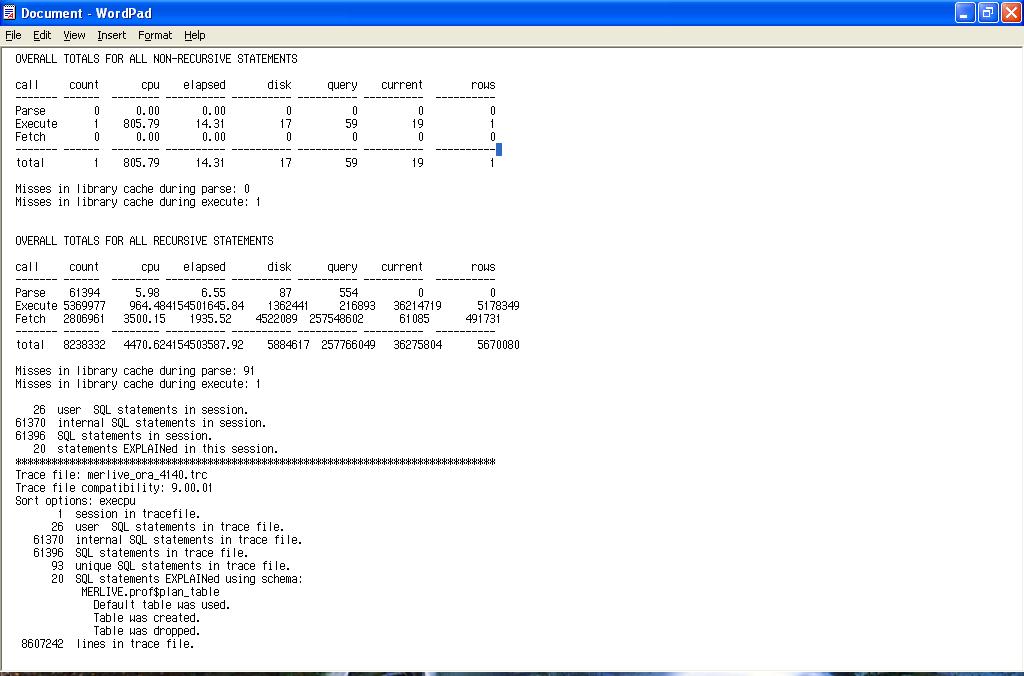
The 'Parse' Line
- High CPU value
This is indicative of hard parsing through poor use of bind variables, the shared pool being too small or the use of sequences without caches specified. cursor_sharing in 8i onwards can alleviate this as can the shared pool partitioning available in 9i for multi processor machines, however the optimum solution is to use bind variables. Note that DDL statements, CREATE TABLE , TRUNCATE etc will always force hard parsing, as such these statements are always parsed, executed and then their parsed representations are thrown away. To quote Tom Kyte from Expert Oracle Database Architecture: "If I were to write a book about how to build none scalable Oracle applications, then Don't Use Bind Variables would be the title of the first and last chapters.". Input bind memory allocation size as described in Jonathan Lewis's blog can also be a contributory factor:-
http://jonathanlewis.wordpress.com/2007/01/05/bind-variables/#more-110 - High parse elapsed times
For releases prior to 9.2.0.5.0 this could possible mean that open_cursors is too low, for releases above this session_cached_cursors (which supersedes this) may not be set high enough. This could also indicate contention on the latches protecting the shared pool to excessive hard parsing by other sessions.
The 'Execute' Line
This is where all the work is done for DML statements. Where as for a SELECT this will be empty as the work is performed in the FETCH. Low execute to parse ratios and numerous statements that are only parsed and executed once could point to poor application design. Where possible a statement should be parsed once and executed many times over. There is always an exception to any rule, the exception here being that one statement can do the job of many statements if your application has scope got using the MERGE statement (9i+) and / or bulk binds. The functionality of the MERGE statement is further enhanced in 10g as a MERGE can now perform the full gamut of DML statements, i.e. INSERT, UPDATE and now DELETE. This is further muddied by 10g performing bulk binding "under the covers" for certain cursors.
- High CPU execute valuesIndicative of poor execution plans, or storage requiring re-organisation, e.g. row chaining migration, poor index clustering factors or indexes with excessive dead space. This will usually be accompanied by large values in the disk and / or query and / or current columns. Your session spinning whilst waiting for a latch can also add to this figure.
- High CPU wait
Hints towards waiting on a none CPU resource, IO being the most usual suspect. - High disk readsFor a database used for online transaction processing or high batch throughput this should low, for data warehousing applications achieving a low number of disk reads may not be achievable. Also note that certain parallel operations such as parallel full table scans will by-pass the buffer cache and incur extent check pointing in the process.
- QueryThis denotes the number of times that the query has to re-construct blocks using undo in order to achieve read consistency. If this is high, ask the question ; are there other session running against the database which are performing needless work, however as Oracle is designed for the multi version-ing of data, a certain amount of block reconstruction from undo is to be expected. However an excessive amount of block re-construction can result from a phenomenon known as 'restart-ing', take for example the following simple UPDATE statement:-
UPDATE mytab
SET cola = cola + 1
WHERE colb = 3Before Oracle will update the relevant rows it has retrieved, it will check whether colb has changed from 3 to any other value since the statement started executing. If this is the case, i.e. another statement that was executed before this one committed shortly before this statement was due to finish, the whole statement will be rolled back and re-executed. It is Tom Kyte who has described this event (in much more eloquent detail) in his Expert Oracle Architecture book as a 're-start'.
- Current
Total number of buffers retrieved in current mode, this only applies to DML statements, if undo has to be used in order to construct read consistent images of blocks, the final images will be materialized as current bocks. - Rows
The value in this column puts the overall efficiency of the query into context, if the ratio of disk reads + query (consistent gets) + current gets is high compared to the number of rows returned, there may be issues with the physical structure of the objects used (chaining, poor index clustering factors etc) or the statement plan may be 'bad'.

{kind=link}