A project I worked on recently used J2EE to implement batch processes. The architecture consisted of a WebSphere application server (version 6.1), Oracle database and a Java client to invoke the batch processes. On initiation, the client retrieves a list of jobs from the database via the application server. The list of jobs was then partitioned into equal sized 'Chunks', calls to a batch control session bean were invoked by threads fired off from the Java client, a chunk of jobs is attached to each thread. On receiving the jobs, the batch control bean invokes other beans to carry out the business logic of the application for each job within the chunk via a loop. In fact this architecture mirrored a batch process solution that can be found devx, to the extent I suspect that this is where it originated from in the first place.
Under this architecture scale out is achieved via IIOP load balancing, whereby the WebSphere workload manager distributes calls made to the batch control bean amongst the nodes in the cluster, or cell to use WebSphere parlance, in a round robin manner. If the CPU capacity of the servers that make up the cell are not uniform, a configurable load balance weighting can be used to redress this inbalance. Refer to
this link from IBM for further details on load balance weighting. WebSphere extended deployment adds further intelligence into the process of distributing the workload via traffic shaping.
Whilst this design and architecture worked, it struck me that there were several ways in which this could be improved on:-
- The client should be as light weight as possible, it should invoke the batch process and report on whether it suceeded or failed. Thus leveraging the qualities of the service the application server provides as much as possible. Specifically, the WebSphere launch client did not in itself provide the same qualities of service as the application server itself, namely workload management, fail over transaction support etc.
- The application should only use transaction context within the application server.
- The client prohibits end user application to Java.
- Using RMI requires the application server RMI boot strap and RMI registry ports to be open.
- A core design pattern should implement the business logic, such that a uniform design principle for followed for all batch jobs.
- Threading should be handled within the application server.
- Inversion of control should be used to decouple the business logic from the batch 'Framework'.
- Although the software used JDBC batching, much better performance and scalability could be realised using oracle.sql.array for array processing.
- Raw JDBC was used for persistance, a better design practise would be to externalise all SQL in the application and configuration.
- For scale out, each node would acquire its configuration, storing the configuration in an LDAP server, a database, JDNI store etc would be much more cluster friendly.
- An XML cache was used to store fixed domain configuration data, whilst this was more efficient than making frequent trips out to the database, a more light weight solution would have been preferable. When in full flight, 20% of each batch processes CPU usage was down to XPath calls associated with this cache.
If you are a sizeable WebSphere shop for which batch processes form a significant part of your IT infrastructure back bone, there is a compelling argument for looking at WebSphere Compute grid. If you are already a major Spring user, Spring batch may worth looking at. However, I'm not going to address the debate of which option is the best fit, suffice it to say both are options available for consideration. Whilst writing this posting, I couldn't help but feel that WebSphere Compute Grid answered a lot of the difficult questions that batch process design asked out of the box.
The salient features of my design are:-
- Batch invocation via synchronous web service calls.
- The web service would use JMS, by placing messages on a JMS queue, message driven beans on each node instigate the batch processing, this is the primary mechanism by which scale out is achieved.
- In addition to the message driven beans facilitating scale out, they provide a means by which the batch process execution is detached from the client, therefore, anything adverse that happens to the client does not affect the batch, this was a conscious design decision.
- Once the message driven had received a message to initiate the processing of the batch, high throughput on each node would be achieved through calls to methods annotated with the JEE6 @asynchronous annotation. I considered this to be the most light weight option available for this purpose, more light weight than a combination of using JMS and message driven beans.
- I was considering using Spring, but as Glassfish 3 is fully JEE 6 compliant, and JEE 6 has virtually closed the gap with Spring in terms of Inversion of Control capabilities. I therefore elected to forego Spring in favour of using JEE 6. Also, at the time of writing this posting , Glassfish 3 was the only JEE 6 compliant application server available.
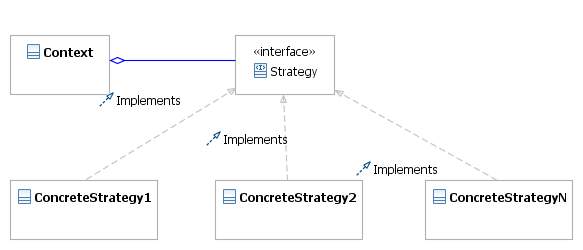
- Implementation of the business logic using the strategy pattern.
- Use of the command pattern in order to determine which strategy is required to implement the strategy.
- Solidity and maturity of a JEE application for transaction management via JTA.
- The use of JEE6 singleton beans annotated for initialisation on application startup for caching fixed domain data.
- iBatis and oracle array processing using the oracle.sql.array class. To achieve raw performance, many people may consider a caching grid style solution at first. However, conventional caching wisdom does not apply to true batch processing, in that the same data item is rarely used more than once during the processing of a batch. Therefore any type of cache, regardless of where it is used in the technology stack will be of limited benefit. If any benefit at all is derived from caching, it will be through write behind and the caching of fixed domain data. iBatis is a "Half way house" solution, in that it is not a full blown object relational mapping framework nor is it as free form as using raw JDBC.
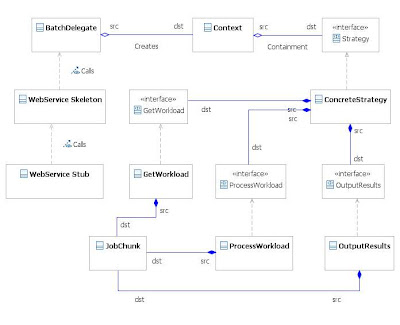
Firstly the strategy pattern. I will not steal anyone's thunder on this, as both Snehal Antani of IBM and a colleague and the Java technical architect of the team in which I work have both proposed this. Below is the essence of the strategy pattern in UML class form. By the way, if anyone want a free UML modelling tool, I can strongly recommend Eclipse Galileo with the modelling bundle, which I used to produce this. Double click on the image to obtain a larger version:-
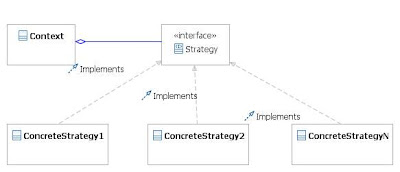
Here is a UML class diagram to represent the command pattern:-
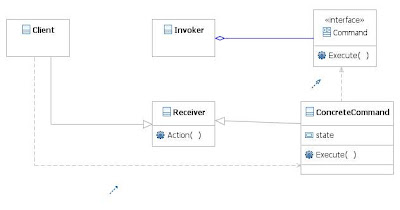
The software architecture consists of the following components:-
1. A web service client and service generated using Axis 2 and Eclipse.
2. On the application server, the skeleton for the web service will instigate the BatchControl session bean, the batch delegate. A stand alone java client could invoke this directly.
3. It will be assumed that only one batch process of a given type will run at the same time, therefore the polling port type only needs the batch process name and not a handle.
4. The batch execution strategy will comprise of three steps:-
- Get workload step, this will obtain a partition ('Chunk') of jobs to be processed.
- Process workload step, this will use asynchronous method calls to process the jobs obtained from the get workload step.
- Output the processed results step.
6. Whilst the batch is running, the client will poll the batch control bean at a frequency determined by a configurable polling period. The polling operation will return the number of jobs processed and the total number of jobs that make up the workload. Another as yet specified web service will allow the last execution of a batch process to be reported on in terms the number of individual jobs that failed and were processed successfully within the batch.
The concept of processing jobs in 'Chunks' will be retained, the three steps of get workload, process workload and output results will be iterated around in 'Chunk' size partitions of the the workload until the total workload is processed.
This is illustrated in the UML sequence diagram below.
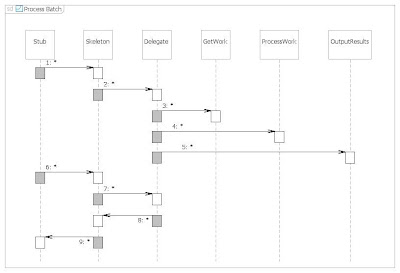
1. Execute batch process.
2. Place the name of the batch process on the execute batch topic of the batch message queue.
3. Execute the get workload element of the batch strategy.
4. Execute the process workload element of the batch strategy.
5. Execute the output results element of the batch strategy.
6. Poll the web service for batch completion.
7. Call the batch delegate to establish whether or not the batch process is still running.8. Return the number of jobs processed and to process to the web service skeleton.
8. Return the number of jobs processed and to process to the web service skeleton.
9. Return the number of jobs processed and to process to the web service stub.
I am yet to established how to track the progress of the batch processes, the problem being around the ability to store state globally across the cluster representing the total number of jobs that the batch is going to process and the total number of jobs processed. The obvious way to do this is to store this in the database, however, for performance reasons I would like to avoid making trips out to the database unless absolutely necessary. A nice solution would be if Glassfish supported something similar to WebSphere's DistributedMap, then as each node in the cluster completes a 'Chunk' of jobs, it will put to this to the hash map, from which the batch delegate (batch control bean) can work out how much of the workload has been processed.
The UML class diagram below illustrates the fleshed out design, click on it to enlarge.
In future postings I will elaborate on the architecture and design with the intention of providing a code skeleton for the prototype.